
Recently I was asked about adding a non-clustered index to a table (let’s call it Images) with just one column. It had been added in the development database and it improved performance dramatically. I looked at it and it had the same key as the clustered index on that table.
In reviewing the query I saw that Images was joined to the other tables in the query, but none of the columns were used, so Images was joined to ensure that values from the other tables had rows in Images. The query plan shows a significantly higher number of reads against Images without the new NCI (non-clustered index) than when it’s present.
Here are the two query plans.
Without the NCI:

With the NCI:
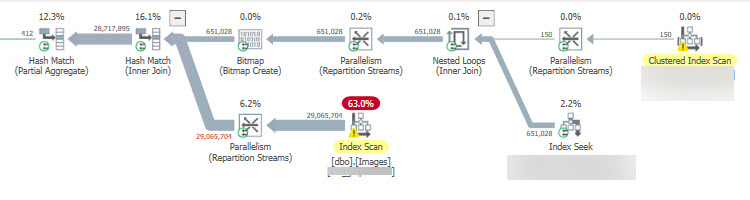
The query with the NCI runs in 3 seconds, but without it runs in 90 seconds. It bothered me to add an index to a large table with the same key as the existing clustered index, so I reached out to my colleagues in the SQL Server community and asked if this was the right approach.
Erin Stellato (b|t) said “that’s what I would do. Particularly if it runs frequently.” Grant Fritchey (b|t) added “Likely is, a scan is necessary, but a scan of the NCI is radically smaller than the scan of the CI, so the optimizer is using that.” Grant’s assessment was confirmed by a senior member of the Microsoft SQL Server team. Erin also added “in addition to the query duration info, if you capture the STATISTICS IO, you can demonstrate the IO improvement, which dovetails with Grant’s comment about the narrower index.”
So, depending on the size of the table, and the query you’re tuning, it’s reasonable to have a non-clustered index on a table with the same key as the table’s clustered index.
1 thought on “Sometimes that Extra Index is the Right One”
Comments are closed.